
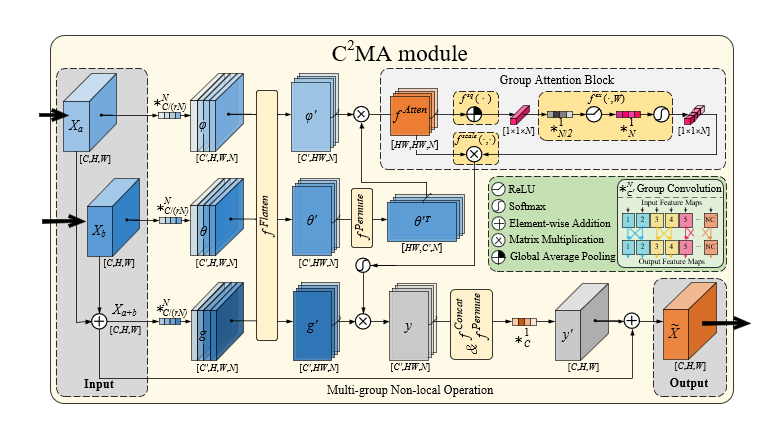
Based on the hypothesis that adding a cross-modal and cross-attention (C2MA) mechanism into a deep learning network improves accuracy and efficacy of medical image segmentation, we propose to test a novel network to segment acute ischemic stroke (AIS) lesions from four CT perfusion (CTP) maps. The proposed network uses a C2MA module directly to establish a spatial-wise relationship by using the multigroup non-local attention operation between two modal features and performs dynamic group-wise recalibration through group attention block. This C2MA-Net has a multipath encoder-decoder architecture, in which each modality is processed in different streams on the encoding path, and the pair related parameter modalities are used to bridge attention across multimodal information through the C2MA module. A public dataset involving 94 training and 62 test cases is used to build and evaluate the C2MA-Net. AIS segmentation results on testing cases are analyzed and compared with other state-of-the-art models reported in the literature. By calculating several average evaluation scores, C2MA-network improves Recall and F2 scores by 6% and 1%, respectively. In the ablation experiment, the F1 score of C2MA-Net is at least 7.8% higher than that of single-input single-modal self-attention networks. More importantly, the ablative analysis results have led to a better understanding of modality-specific and cross-modal attention and reveal that the proposed new model produces a better dependency between the different image maps or modalities than using other self-attention-based methods. This study demonstrates the advantages of applying C2MA-network to segment AIS lesions, which yields promising segmentation accuracy and achieves semantic decoupling by processing different parameter modalities separately. In addition, this study also demonstrates the potential of applying cross-modal interactions in attention to assist in identifying new imaging biomarkers for more accurately predicting AIS prognosis in future studies.