
This is the second in a series of articles on the dramatic transformation taking place in health informatics, in large part because of the new Health Level 7 (HL7) Fast Healthcare Interoperability Resources (FHIR) standard. The first article provided background on health care, electronic health record (EHR) systems for physicians, and related challenges, and described the potential of interoperability to help overcome these challenges. In this article, we consider FHIR in sufficient detail to provide interested readers with a basis for further exploration. In the next article, we will see how FHIR is being used as the basis for a long-sought “universal health app platform” that can operate with any FHIR-enabled EHR. The articles in this series are intended to introduce researchers from other fields to health informatics and assume no prior knowledge of health care or health informatics. They are abstracted from the author’s book Health Informatics on FHIR: How HL7’s New API is Transforming Healthcare (Springer International Publishing).
The first article of this series mentioned that, after the success of its new messaging standard for electronic health record (EHR) systems, Health Level 7 (HL7) found it difficult to develop and widely deploy a standard for the rich representation of clinical data for use in patient care. This was due, in large part, to the complexity of medicine and the resulting complexity of the clinical terminologies developed to represent it.
To give one example, the Systematized Nomenclature of Medicine–Clinical Terms (SNOMED CT) is arguably the most comprehensive of these terminologies. It contains over 300,000 clinical concepts and more than 1 million relationships among them. The Fast Healthcare Interoperability Resources (FHIR) standard seeks to provide a sufficient degree of interoperability to be useful while avoiding much of the complexity that a complete interoperability solution inevitably entails. To understand this, it is useful to define three interoperability levels.
Transport Interoperability
The simplest form of interoperability transports data from one system to another without regard to its content or purpose. A fax machine is an example of simple transport. In health care, a technology called Direct transports encrypted clinical data by attaching the data to secure e-mail. The e-mail system moves the data no matter its content or purpose. Any parsing of the data for use by the receiving EHR is entirely a matter for that EHR. But such parsing can be difficult or virtually impossible to do, depending on the content and format of the data.
Structured Interoperability

The more advanced form of structured interoperability places specific data fields in positions that indicate their purpose. The receiving EHR can detect that a particular field is the name of a specific laboratory test, its result, or, optionally, a code for the test because each of these bits of information is in a prespecified field within the transported entity. As Figure 1 shows, HL7’s first messaging standard provides an example of structured interoperability.
Semantic Interoperability
Semantic interoperability is the highest form of interoperability and requires sufficient shared standards to enable the receiving system to store and use data from a sending system as though the data had originated in the receiving system. For example, clinical-decision support uses data about a patient and a rule- or analytic-based approach to make diagnostic or treatment recommendations specific to that patient. If semantic interoperability is available, the clinical data from another EHR system could still be understood and trusted sufficiently for use in actual patient-care decision-making. As we will see, FHIR provides transport and structured interoperability, and it also can provide a degree of semantic interoperability on a field-by-field basis.
FHIR Resources
In the first article of this series, we saw that each individual EHR is typically proprietary and has its own way of representing clinical data and its own data models. To FHIR-enable an EHR, the EHR’s clinical data must be mapped to the FHIR data model as instantiated in FGIR resources. Some 150 resources are anticipated in the standard. Not all of these are clinical, but a few key clinical resources (patient, provider, conditions, observations, medications, and allergies/intolerances) are often sufficient to develop useful clinical tools. Each of these resources is defined in detail by the standard and can be instantiated in JSON, XML, or RDF, with JSON being by far the most commonly used.
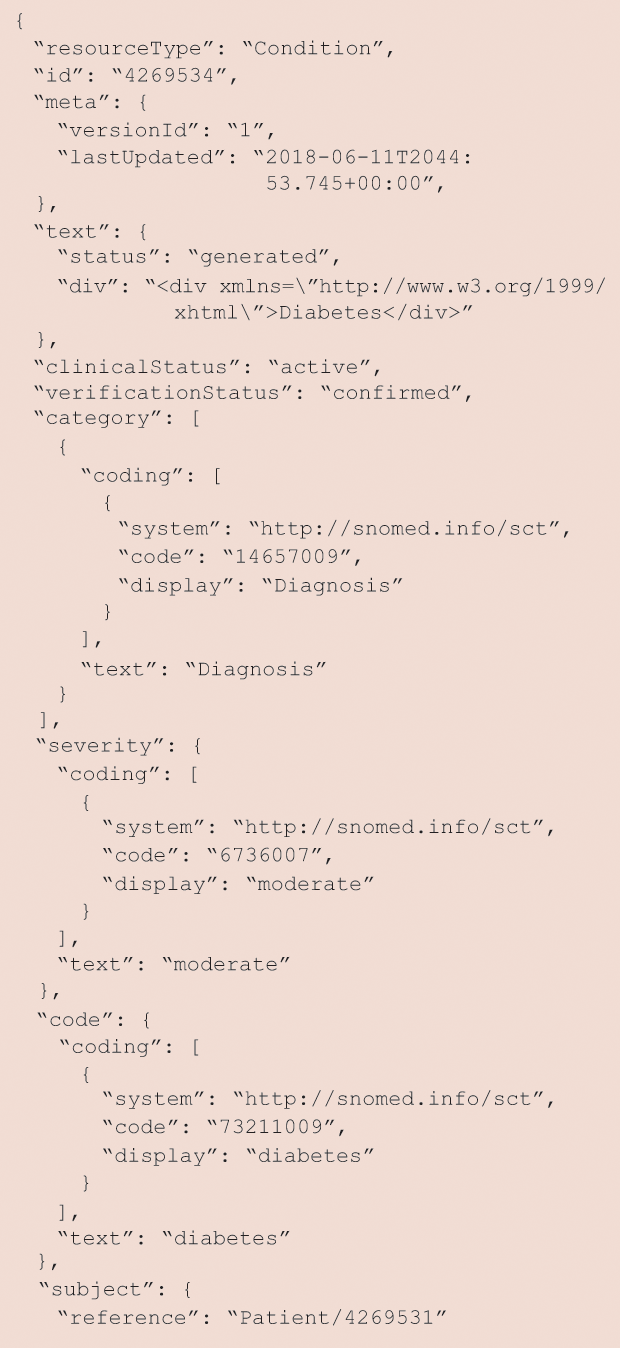
Figure 2 provides a simple example of a JSON-formatted condition resource and illustrates another key design decision. FHIR incorporates existing standards for clinical data. In this case, the patient’s diabetes is coded into the SNOMED CT clinical health terminology mentioned earlier. You should find it far more readable than the EDI/X12 message in Figure 1. Can you find the SNOMED code for diabetes in this resource?
It was noted previously that FHIR does provide a limited degree of semantic interoperability. This is accomplished through the use of value sets that define the allowed values for a specific field in an FHIR resource. Table 1 lists the allowed values for the category of an allergy/intolerance FHIR resource.
Table 1 – The Allowed Values for the Category of an Allergy/Intolerance FHIR Resource
| Code | Display | Definition |
| food | Food | Any substance consumed to provide nutritional support for the body |
| medication | Medication | Substances administered to achieve a physiological effect |
| environment | Environment | Any substances that are encountered in the environment, including any substance not already classified as food, medication, or biologic |
| biologic | Biologic | A preparation that is synthesized from living organisms or their products, especially a human or animal protein, such as a hormone or antitoxin that is used as a diagnostic, preventive, or therapeutic agent |
FHIR Application Programming Interface
In the first article of this series, we saw that FHIR resources are retrieved using a Representational State Transfer (REST) Application Programming Interface (API). An API can be thought of in nontechnical terms as a form of “contract” guaranteeing that if one sends a message to a remote server in a specific format, one will always get a response. The string of characters, numbers, and symbols at the top of your browser when you shop or search for information is usually a REST API. This is, of course, critical for the Internet, where billions of these transactions occur daily among client devices, such as personal computers, smartphones, and servers, located virtually anywhere.
FHIR resources are retrieved from an EHR using a specific REST API. Here is a basic example of the three-part structure of an FHIR API to retrieve (GET) information:
http://hapi.fhir.org/baseDstu3/Condition?code=http://snomed.info/sct|73211009
The first part (blue) specifies the server where the information is stored; the second part (green) specifies the type of resource that is desired; the third part (brown) provides sufficient information for the server to retrieve the correct resource(s). Note that, in this case, the specification is made using the same SNOMED CT code for diabetes that we saw in Figure 2. Thus, this API is asking for all patients on the specified FHIR server (hapi.fhir.org/baseDstu3) who have a diagnosis (condition resource) SNOMED CT-coded as 73211009.
FHIR Profiles
The FHIR standard is intentionally quite nonspecific as to the purpose (use case) of interest for a particular application of the standard. To prevent the standard from becoming too complex, FHIR resources specify only the data that 80% or more of the standards developers feel is necessary in each resource. FHIR profiles provide additional specification, are themselves instantiated in a FHIR resource, and further define how the standard is to be used. For example, they might specify allowed values for one or more fields (ValueSets). They might also specify additional fields not necessary to include in the FHIR specification (Extensions). An example of an extension from pediatrics is the age at which a childhood allergy resolved. This field would not be needed for adult care, which predominates in health care, so it fails the 80% test. HL7 maintains an extension registry to avoid duplication.
FHIR Applications
The initial FHIR standards development effort is centered around the care of patients, one at a time. Individual FHIR servers can and often do provide support for search efforts that can extend across patients, as we saw earlier in the example of an API intended to retrieve all patients from a specific FHIR server with diabetes coded as SNOMED CT 73211009. In that example, it was the free, public, nearly complete implementation of the FHIR specification using a 100% open-source software stack in Java hosted by University Health Network at https://fhirtest.uhn.ca/.
Performing a search such as this on an actual EHR system containing millions or even billions of data items for thousands of patients would risk sacrificing system performance, so it is impractical in most cases. To provide a rich search and data-query capability and support important applications that cut across many patients, a non-real-time FHIR Bulk Data Query Protocol is under development. Among these applications is population health, in which a clinical practice manages all its patients with a specific condition, such as diabetes, in a more continuous way to spot those who may be in need of help before they require expensive emergency-department or even hospital care. Another example application is public health, which is, according its mission, interested in the aggregated health status of the entire population of some geographic entity, such as a country. Of course, applications of bulk for research should be especially promising.
FHIR Adoption
The 21st Century Cures Act of 2016 requires that EHR systems provide a patient-facing API to maintain their federal certification. It is widely anticipated that, once HL7 releases the first normative version of the standard, the federal mandate will be specified as the FHIR API. Indeed, key U.S. healthcare entities, including Medicare, the largest U.S. healthcare payer, and the Veteran’s Administration (VA), the largest U.S. healthcare system, have already adopted FHIR. Medicare’s new Blue Button 2.0 API provides its 58 million recipients aged 65 and over with access to their Medicare data using FHIR. The data they can access include their type of Medicare coverage, drug prescriptions, primary care treatment, and cost. Beneficiaries also have full control over how their data can be used and by whom.
The VA has developed Lighthouse, a similar FHIR platform for VA patients to access their health data via FHIR. The previous article in the series described Apple’s use of the standard to provide a way for iPhone users to retrieve and aggregate their medical records on their phones. This means that patients being seen by multiple physicians may become the repository of their complete medical record. Apple is also now providing an API to developers for whatever purposes iPhone users find valuable. The next article in this series will discuss FHIR apps, the vehicle through which Medicare and VA patients, iPhone users, and others will usually access and utilize health data represented as FHIR resources.
Web Resources
- Fast Healthcare Interoperability Resources. (2018). [Online].
- UHN HAPI Server. (2018). [Online].
- clinFHIR Launcher. (2018). [Online].