
Scientists striving for impact in their fields and to develop their own careers must publish papers that represent new and important science, typically in a peer-reviewed journal. The number of scientific articles published has doubled every nine years since WWII, and now stands at more than 3 million peer-reviewed articles annually from more than 34,000 scholarly journals.
Publishing strong research requires a thorough understanding of the field, a mastery of the relevant literature, an understanding of relevant potential collaborators, reviewers, and sources of research funding, and familiarity with possible publication venues and dates. However, the capacity of scientists to absorb journal articles hasn’t changed over time—even the most diligent scientists read no more than a few hundred journal articles per year. This trend of information overload makes it increasingly difficult to develop and publish high-impact research based on a mastery of the current state of the art. In particular, the accelerating volume of research published—particularly in dynamic fields like Computer Science and Biomedicine—means that only those most connected are able to keep up with the relevant developments in a field. More and more, the information a scientist needs is scattered among a fragmented collection of static pdf documents, hosted on a variety of academic publisher websites, and other media formats, such as video and slides from conference presentations and blogs.
Information overload represents a fundamental challenge to science because it creates incentives for safer, incremental work at a time when the world looks to scientific institutions for breakthroughs to address fundamental challenges to our environment, health, and economy. Information overload requires scientists to spend more time in research planning and literature review, which increases the odds that another scientist will publish on their topic first. As a consequence, this creates a perverse incentive to publish quickly to avoid being preempted, ultimately leading to less risky, more incremental topics. In aggregate, science suffers and potential breakthroughs lie undiscovered. Particularly disadvantaged are junior scientists and those without strong institutional support who face a steeper slope to develop and publish high-impact research.
Semantic Scholar and Artificial Intelligence
Information overload is a challenge that the Allen Institute of Artificial Intelligence (AI2) chose to address when it launched Semantic Scholar in 2015. Founded by the late Microsoft cofounder Paul Allen, with a mission to invest in high-impact Artificial Intelligence (AI) research for the common good, Semantic Scholar is a free academic search engine. Semantic Scholar represents the application of years of research in information extraction, natural language processing, and ontology alignment to the problems of information overload in research. The foundation of this work is a knowledge graph created through semantic analysis of more than 40 million publications in computer science and biomedicine, including the complete contents of PubMed, Medline, DBLP, and arXiv as well as millions of full-text papers sourced through relationships with top academic publishers. Semantic Scholar is structured as a search tool with a traditional search bar interface, as well as navigation by papers, topics, and authors most closely related to the information in scope.
Powered by an information extraction model we have named ScienceParse, Semantic Scholar’s knowledge graph is constructed from key metadata extracted from PDFs representing papers, authors, and topics. ScienceParse also uses information extraction methods to identify and extract more than 400 million citations from these documents. We have built a model to identify the most important of these citations, which we describe as “Highly Influential” citations. Through semantic analysis of the text surrounding the citation, we identify those that reference the preceding research that has had the greatest influence. This smaller number of “highly influential citations” (40 million) is a more focused signal for researchers seeking to identify the most important and relevant works to their interest.
A complimentary methodology for information extraction developed by Semantic Scholar is DeepFigures, a technology that extracts the figures and tables from papers (below). These appear as thumbnails within Semantic Scholar’s summary of each paper, and simplify the process of understanding a paper’s relevance.

Another novel application of AI technology supports the automated creation of pages summarizing scientific topics. While most scientists are experts in their fields, developments in new and related fields are often interesting clues to new avenues of research. Semantic Scholar has extracted more than 300 million topic mentions and clustered them into a topic ontology of over 400 thousand topics in Computer Science and Biomedicine. Each topic page represents the most relevant and recent literature about the topic, providing a much easier way to evaluate a new research area or understand the state of the art in a new field.
Adding context to research
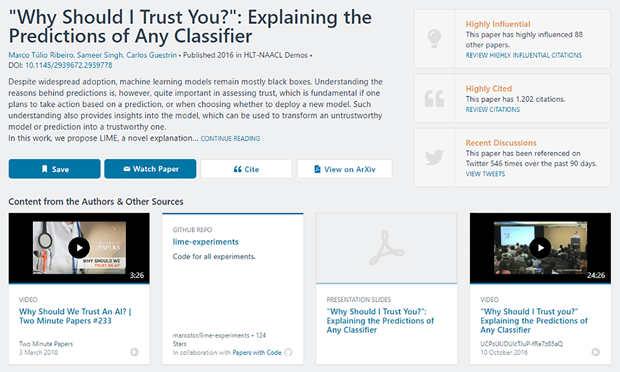
Citation by peers is a well-established approach for evaluating the significance of a piece of research. However, scientists increasingly rely on other media to communicate their own research findings and learn about others’ work. A recent addition to Semantic Scholar is seven categories and more than 10 million instances of external content to paper summaries. Added content types all reference the paper they are presented with and include videos, presentations, Twitter mentions, blogs, news, code libraries, and clinical trials. By adding important additional content to Semantic Scholar, scientists can understand the importance of the paper in its larger context.
For example, recent findings covering the impact of sugar and artificial sweeteners on strokes or dementia are being heavily discussed on blogs and in the news, which provides an early signal to understand conclusions from the paper since it has not yet been cited by follow-up research. By placing research papers in the context of related research or within a broader theme, Semantic Scholar helps scientists cut through information overload to quickly draw conclusions about the research under review. For example:
- Social media is often where emerging research is first actively discussed before being covered by mainstream media and blogs. We found and matched dozens of such discussions on Twitter to a recent paper that presented a security analysis of 5G technology, highlighting a new trend.
- Clinical trial information provides researchers additional context to assess the validity of biomedical claims made by research studies. We matched clinical trial information to a study that found that intensive glucose lowering increases mortality in high risk patients with type 2 diabetes.
- Code libraries and data sets are an important aspect of making research reproducible. When matched with a recent paper on how to make AI more understandable and accompanied by a video summarizing the work by the Author, the research is easier to understand and reproduce (below).
Increasing research impact
Collectively, Semantic Scholar’s content, technology, and AI-powered features help scientists increase their impact by making it much easier to find and understand the most relevant new science. In contrast to simple queries that can be answered by a keyword-based search engine, understanding science well enough to build on it requires the discovery, comprehension, and synthesis of multiple types of information.
To understand the state of the art in a domain, one must not only survey all the relevant literature, but assess it for relevance and identify and review relevant related works until you have reviewed the literature comprehensively. Missing an important prior work can seriously undermine the impact of a research project, and even experts in a field struggle with this task. Semantic Scholar’s technology replaces much of human drudgery of literature review.
Another important factor of research impact is knowing who else is working in an area, what they have written, and how they relate to one another. This information has historically been acquired through experience in the field, conference attendance, and relationships with more senior researchers, and is used to shape research goals and identify potential collaborators or reviewers. As science has become larger and more global, it has become more difficult to identify the most reputable and current authors in a field. Semantic Scholar addresses this problem by summarizing each author’s works and their network of influence, greatly simplifying the process.
Understanding how previous research was done is an important part of conducting high-impact work. This has often involved research into previously used experimental methods, data, and code. Efforts to archive this information systematically are still in early stages of adoption, and as a result, much time and effort is wasted in attempting to recreate or improve experimental conditions. Semantic Scholar’s early efforts to find and match this content to research reduce the time and effort needed to conduct new experimentation.
As noted, the initial promise of the World Wide Web to enable the free exchange of ideas among scientists has been diminished by information overload. We offer Semantic Scholar as a tool to combat information overload and empower scientists to focus on high-impact research. Our core information extraction technology, ScienceParse and DeepFigures, and a copy of our knowledge graph are available for non-commercial use here.