
By the numbers, 2016 was not a good year for the U.S. pharmaceutical industry. As of early December, only 19 new drugs had been approved by the Food and Drug Administration (FDA), fewer than half of those approved in 2015 and the lowest number since 2007. Further, the FDA approved only 61% of submissions in 2016, compared to 95% in 2015 [1]. And, among the largest companies, the return on investment for research and development (R&D) fell to 3.7% [2].
Despite these discouraging statistics, the pharmaceutical industry remains an integral part of the healthcare ecosystem, bringing drugs to market to address diseases of all types. Increasingly, however, the industry faces growing pressure to improve overall productivity and reduce development time to maximize the period of patent protection, during which R&D costs can be recouped. Pharmaceutical investment in R&D in the United States was roughly US$50 billion in 2015 (and €30 billion in Europe), but despite these staggering amounts, there has historically been little correlation between investment and the number or effectiveness of drugs brought to the market (Figure 1) [3], [4]. The average cost of successfully developing one drug, including the failures that invariably occur, is US$2.6 billion. Still, worldwide sales of drugs passed US$1 trillion in 2014 and are expected to escalate to US$1.3 trillion by 2018.
![Figure 1: Pharmaceutical R&D investment compared to the number of new chemical entities (NCEs) introduced in the United States, 1991–2012. (Image courtesy of [4].)](https://www.embs.org/wp-content/uploads/2017/05/keshava01-2678638.jpg)
The Drug Development Pipeline
The drug development process, in its entirety, is extremely complicated and multidisciplinary. Unlike many challenging problems solved by engineers, no overall model serves as a basis for optimization and improvement. At the same time, pharmaceutical companies are generating ever-increasing amounts of data, driven mostly by sequencing of human genomes; consequently, companies are beginning to realize the value of the data scientist in developing and applying algorithms that uncover efficiencies throughout the pipeline. Not surprisingly, as pharmaceutical companies strive to produce drugs that satisfy unmet clinical needs while also preserving their own financial health, there is a growing belief that data science and approaches from engineering and computer science will be critical for the long-term future of the industry.
The pharmaceutical drug pipeline is actually the concatenation of many smaller stages (see Figure 2), and, on average, 12 or more years of R&D are required before a New Drug Application (NDA) can be submitted to the FDA. The overall goal is to produce drugs that are efficacious compared to an existing standard of care while also minimizing side effects. Figure 2 illustrates the major segments of the drug discovery and development pipeline and the proportional number of compounds that are commonly investigated to yield one drug approved by the FDA. At every stage, but particularly during the early stages before the best single compound to address a disease is identified, decisions about advancing certain compounds and halting others are made based on a wide variety of experimental data, as well as historical data obtained from other experimental research. In the larger context of optimizing drug development, “failing fast” (terminating further development of compounds based on unsatisfactory performance) is especially important, given that the cost of moving compounds forward increases at every successive stage of the pipeline—and rises dramatically when human trials begin.
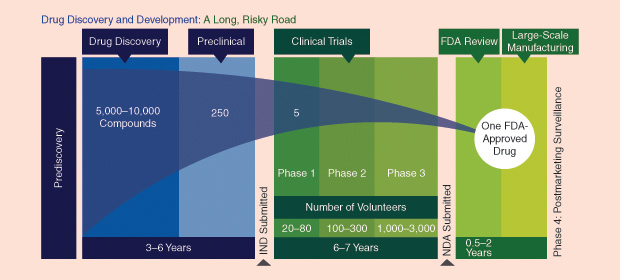
The basis for a new drug is initiated when an entity in a biological pathway (also known as a target) is hypothesized as critical to the start or development of a disease. Then, the search for a chemical compound to interact with the target is undertaken. If successive stages of preclinical testing are successful, an Investigational New Drug (IND) application is filed with the FDA. The clinical phase is the most expensive part of the drug pipeline and begins when the compound is tested in successive clinical trials. Phase I and II trials are designed to test safety and efficacy, respectively, in small populations.
The criteria for a compound to progress beyond Phase I and II trials are frequently based on exceeding the efficacy and safety profiles of existing compounds in the market or those in development whose results have been published. Continuous and accurate collection and curation of competitive intelligence from the public literature, therefore, is an important asset to place the development of a compound in context with competing compounds and to define the barrier to enter the marketplace. Knowledge-management systems based on semantic technology enable decision makers to rapidly assess the existing marketplace and develop strategies.
Viewed within the constraints of a limited budget to advance multiple compounds forward, a compound whose Phase I and II results do not meet or exceed thresholds may be deprioritized until the funds exist, possibly by partnering with another company, or stopped altogether. An alternative may be to position the compound to address a different disease state where the barrier to entry is not as high, particularly if the underlying biology and previous trial results are supportive of the change.
Phase III trials are commonly performed on a significantly larger population. The results from Phase I and II are carefully scrutinized to understand the pharmacokinetics and pharmacodynamics (PK/PD) of the compound and to assess the right dosages to be tested. They can also provide inputs on the inclusion and exclusion criteria for patients as well as the necessary companion diagnostics, which are medical devices or tests that identify the right patients for a trial. The number of patients involved in a Phase III trial depends on the disease state, but in some cases, particularly cardiovascular trials, the number of patients can exceed 10,000. If Phase III trials succeed and the FDA approves the application to market the drug, there may still be subsequent postmarketing trials (Phase IV), the goals of which are to investigate the long-term behavior of a drug or to demonstrate its utility for a disease state different from the original.
The use of data to find efficiencies in drug development can’t come too soon. The discovery and development of drugs are based on the attrition of hypotheses, most of which are invariably bound to fail. Only five in 5,000, or 10%, of the drugs that begin preclinical testing ever make it to human testing, and only one of these five is ever approved for human use. Collectively, the data generated for a single compound through the entire drug pipeline span a broad range of technologies, modalities, species, and patients. Many pharmaceutical companies are looking inward at their data warehouses and using data science to find ways to cut costs and time and increase overall productivity. The following are specific areas where data-driven approaches address specific challenges in drug development.
Clinical Trial Planning
Phase III clinical trials are expensive efforts frequently undertaken with both cost and time pressure, particularly in light of the fact that the period of patent exclusivity begins roughly around the time a drug begins its first clinical trials. Phase III trials are commonly conducted at more than 100 sites in ten or more countries, each having its own regulatory requirements. Because drugs are increasingly being designed for patients meeting very specific criteria, companies frequently compete to recruit the same patients. The inability to recruit, enroll, and randomize sufficient numbers of patients incurs delays and increased costs; if the drug is ultimately approved, these delays further erode the time over which the manufacturer can recoup its costs during the period of patent exclusivity.
To make trial planning more quantitative, pharmaceutical companies are using data-driven approaches to build rigor into the way they assess the feasibility of successfully executing clinical trials within time and cost constraints. Existing techniques to identify where desirable patients are most likely to be found extrapolate incidence rates and prevalence of diseases from the literature, but accurate estimates may be available only for more developed countries and more common diseases. Moreover, regional estimates within a particular country may be difficult to identify.
To address these limitations, trial feasibility planners are obtaining highly localized and up-to-date estimates of disease prevalence by constructing cohorts in commercially available payer claims databases and electronic health records data warehouses. Some vendors have also built alliances with hospitals to query their patient data warehouses, apply specific trial criteria, and return aggregate counts of patients meeting the requirements. Furthermore, in some cases, vendors and hospitals obtain preconsent from patents in hospitals so they can be invited to enroll in the trial immediately after they have been identified as meeting the criteria. This whole process maintains the privacy of the patient data because no data values or patient identifiers are exported outside the hospital firewalls.
Estimating candidate patients from databases enables machine- learning approaches to intersect with epidemiological measures that then build predictive models to anticipate the number of patients falling within a specific demographic who can be recruited from a specific country, and possibly regionally. Inevitably, with the integration of different data streams, clinical trial planning will become a rigorous, model-based activity, the performance and reliability of which will ultimately be well understood.
Drug Repurposing
The accumulated set of aborted compounds that fall out of the pipeline provides a means to learn from failure. Sometimes, failure inspires a new attempt that modifies a molecular structure or selects an alternative method of delivery. Or, in instances where the scientific or strategic case for advancing a compound is not sufficiently compelling, the compound is effectively parked.
Drug repurposing is the attempt to take a drug designed to address a specific disease and identify an altogether different disease for which it could be used. In some cases, the drug can be one whose development was discontinued, and in other cases the drug may be one that is currently on the market. Repurposing usually occurs when a scientist pieces together a hypothesis that the mechanism of action by which a drug interacts with a biological target for one disease may also be applicable for another disease state. Laboratory and possibly clinical tests might then evaluate the new hypothesis. If the tests prove successful, that evidence could be submitted to the FDA for approval to market the drug for the different disease, with substantially reduced investment of time and money.
Recent efforts, however, have capitalized on matching the pattern induced by cellular transcriptional activity when a disease is active with the corresponding reciprocal transcriptional pattern induced by drugs in human tissue. The discovery through computation of complementary “drug– disease pairs” is further aided by large public repositories of sequencing and gene expression data (e.g., the Gene Expression Omnibus; Drug versus Disease; the Database for Annotation, Visualization, and Integrated Discovery; and the Gene Set Enrichment Database). The ability to systematically match drugs to diseases using transcriptional “fingerprints” creates the potential for data-driven hypotheses that can be subsequently validated through additional animal studies. The results of such approaches have demonstrated initial success in identifying possible new uses for existing drugs in different therapeutic areas than the ones for which they were originally intended [5]. Drug repurposing is viewed as an important objective of one of the most recently founded National Institutes of Health centers, the National Center for Advancing Translational Science.
Wearables and Smartphones
Wearables and smartphone technology are also being used to improve clinical trials. Clinical trials are designed to test one or more hypotheses for which patients enter a particular arm of a clinical trial, and patients are then monitored to determine whether they achieve a prespecified clinical endpoint that characterizes the efficacy of the intervention. Clinical endpoints vary depending on the disease state. For example, in respiratory disorders, a key goal for drugs is to minimize the number of pulmonary exacerbations; a clinical trial in which one arm receives a drug and another receives a placebo may ultimately be judged according to whether the rates of exacerbation differ significantly. Exacerbations, however, are discrete events that occur relatively rarely. Moreover, although the proportion of exacerbations that occur in each arm determines the overall outcome of the trial, continuous measurements leading up to and following exacerbations could provide unique scientific knowledge that helps characterize and ultimately predict the occurrence of exacerbations.
Wearable technology provides a way of unobtrusively capturing continuous physiological measurements that may predict the occurrence of outcomes. Moreover, in the case that wearable measurements can replace more complicated, subjective, and expensive measurements of outcomes (i.e., serve as a surrogate endpoint), clinical trials can become less expensive, faster, and more accurate. Particularly in the case of neuroscience, where the pathophysiology of diseases is frequently poorly defined, the only existing measures to define the evolution or the outcome of neurological disorders are subjective measures of cognitive ability or point scales that capture patients’ quality of life and levels of self-sufficiency. The possibility of characterizing disorders and medical events that are currently poorly defined or expensive to measure makes wearable technology an attractive option.
Likewise, smartphone apps are being aimed at the critical problem of medication adherence in conducting clinical trials (as well as among the general population). Although patients are prescribed a drug regimen when they enter a clinical trial, there is no guarantee that they will follow the regimen as directed. Forgetfulness and confusion about the prescribing instructions are main causes for lack of adherence. Recent studies of medication nonadherence report that nearly 30% of patients in clinical trials may be discarding their medication before their study visits. In light of these statistics, it is not surprising that the efficacy and toxicity estimates in clinical trials will be skewed and that the estimates of impact on the general population will be inaccurate.
One solution being considered is using the smartphone as a platform to encourage medication adherence. Implementing reminder functions and avatars that can engage patients and help them maintain their dosing schedules is a strategy for maximizing adherence. Especially in the case of chronic disease such as diabetes, which frequently requires multiple medication doses per day and persistent monitoring of glucose levels, pharmaceutical companies are beginning to find that outcome rates for their drugs improve when the prescription is accompanied by a smartphone app to guide patients.
Looking Forward
The pharmaceutical industry has firm historical roots deep in the life sciences, yet it is beginning to recognize the importance of data science—and, more formally, engineering and computer science methodologies that fully exploit the data it generates—in potentially transforming the industry. The advent of a plethora of data-rich technologies and pressure to increase productivity and reduce the time and cost of bringing drugs to market are leading the pharmaceutical industry, like many others, to pivot toward a data-centric ethos of innovation and value creation. As the evolution toward a digital healthcare system continues and the practice of clinical medicine intersects with computer science and engineering, several large and meaningful opportunities for the pharmaceutical industry to leverage decades of successes in engineering and data science are already transforming life around us.
References
- H. Ledford, (2016, Dec.) “US drug approvals plummet in 2016,” Nature. [Online].
- Deloitte Centre for Health Solutions, (2016). “Balancing the R&D equation: Measuring the return from pharmaceutical innovation 2016,” London, U.K. [Online].
- Pharmaceutical Research and Manufacturers of America. (2015, Apr.). 2015 biopharmaceutical research industry profile. Washington, D.C. [Online].
- S. K. D. Fernald, T. C. Weenen, K. J. Sibley, and E. Claassen, “Limits of biotechnological innovation,” Technol. Invest., vol. 430204, no. 4, pp. 168–178, July 2013.
- J. T. Dudley, M. Sirota, M. Shinoy, R. K. Pai, S. Roedder, A. P. Chiang, A. A. Morgan, M. M. Sarwal, P. J. Pasricha, and A. J. Butte, “Computational repositioning of the anticonvulsant topiramate for inflammatory bowel disease,” Sci. Trans. Med., vol. 3, no. 96, p. 96ra76, Aug. 2011.