
This is the sixth and last article in a series on the dramatic transformation taking place in health informatics in large part because of the new Health Level 7 (HL7) Fast Healthcare Interoperability Resources (FHIR) standard. The first article provided the background on healthcare, electronic health record systems for physicians, and the challenges they both face along with the potential of interoperability to help overcome them. The second introduced the basics of the FHIR standard and some suggested resources for those who are interested in its further exploration. The third introduced SMART on FHIR, which, based on its wide adoption, has become the default standard FHIR app platform. The fourth looked at clinical decision support, arguably the single most important provider-facing use case for FHIR. The fifth introduced the personal health record and tools that can utilize the data stored in it as an important use case for FHIR in support of patients. This article looks at the future uses of FHIR with a particular emphasis on those that might impact on research uses of health data. The articles in this series are intended to introduce researchers from other fields to this one and assume no prior knowledge of healthcare or health informatics. They are abstracted from the author’s book Health Informatics on FHIR: How HL7’s New API is Transforming Healthcare (Springer International Publishing).
The Road Ahead
A careful reading of the first five articles in this series might suggest that FHIR use cases are limited to “one patient at a time” scenarios involving care of that patient by their provider or the use of FHIR-based tools by the patient on their own. To a large degree, this has been true, but the FHIR development community has expanded its scope to include the extraction of specific data abstracts from a patient’s chart and large datasets from electronic health record systems of even larger clinical data repositories. In this article, we will discuss two new FHIR technologies: FHIRPath and the FHIR Bulk Data Access protocol. In both cases, an opportunity is presented to experiment with the technology to gain an appreciation for its capabilities.
FHIRPath is a path-based navigation and extraction language, somewhat like XPath. The key difference is that while XPath uses path expressions to select nodes or node-sets in an XML document, FHIRPath operations navigate a large FHIR JSON bundle to extract specified content such as a patient’s current problems or medications. FHIRPath operations are expressed in terms of the logical content of hierarchical data models, and support traversal, selection, and filtering of data.
The excellent clinfhir site is maintained by New Zealand-based FHIR guru David Hay. It provides numerous tools for experimenting with FHIR and related FHIR technologies and tools such as ValueSets that specify the allowed values for a specific data element such as the patient’s gender and Implementation Guides that specify how FHIR can be used to meet the requirements of a specific use case such as EHR Meaningful Use reporting requirements in the U.S.
FHIRPath
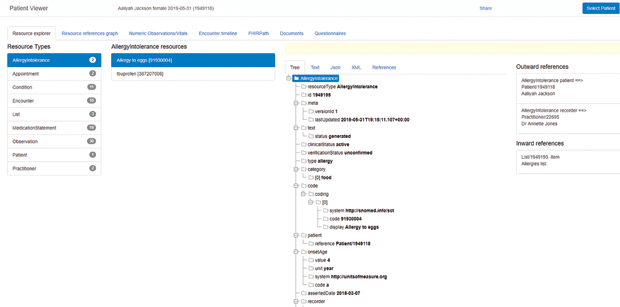
To gain an appreciation for FHIRPath, visit clinfhir and select the Patient Viewer Module at the top of the main page menu. Click Select Patient and then Add New Patient. Make certain that Generate Samples is checked, and then click Generate Patient. Click Close and you should see something like Figure 1.
The list of Resource Types along the left shows what was generated in this make-believe patient record. In this case, the patient has two allergies or intolerances, 11 medical conditions, and 19 medications. Clicking on any of these provides an excellent way of exploring FHIR. In Figure 1, the “Allergies/Intolerances” resource type has been expanded to show the two specific instances, and the “Allergy to Eggs” resource has been further expanded to show its FHIR resource in a human-friendly tree view.
Clicking the FHIRPath link in the top menu provides a way of presenting the patient’s entire record as a single FHIR bundle. From there, inputting the simple FHIRPath expression:
“Bundle.entry.where(resource.resourceType=‘Patient’).resource.name.family”
will extract the patient’s family name. I leave it to interested readers to explore more complex queries that might, for example, extract and display the complete list of medical conditions or medications.
FHIR Bulk Data Access
While FHIRPath is a useful tool for extracting specific information from an entire patient record, a research effort might well be interested in precisely specifying and extracting data as FHIR resources form a large cohort of patient records. Beyond the challenge of the specification itself, adding such a capability to an operational electronic health record system creates the real potential for performance degradation. The proposed solution is the FHIR Bulk Data Access protocol.
The group that developed this technology provides this explanation of its purpose: “Providers and organizations accountable for managing the health of populations often need to efficiently access large volumes of information on a group of individuals. For example, a health system may want to periodically retrieve updated clinical data from an EHR to a research database, a provider may want to send clinical data on a roster of patients to their ACO to calculate quality measures, or an EHR may want to access claims data to close gaps in care. In most cases, access to these bulk-data exports is preauthorized between the data holder and the data requester. The data exchange involves extracting a specific subset of fields from the source system, mapping the fields into a structured file format like CSV, and persisting the files in a server from which the requester can then download them into the target system. This multistep process increases the cost of integration projects and can act as a counter-incentive to data liquidity” (https://github.com/smart-on-fhir/fhirbulk-data-docs).
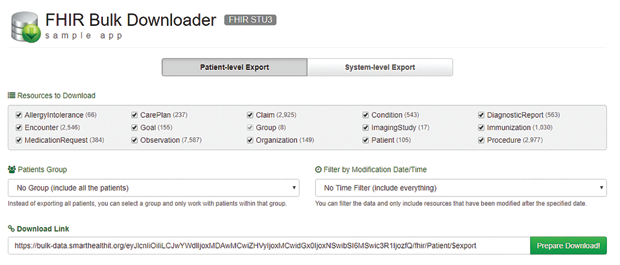
The protocol is an extension of the SMART specification that provides a way of submitting a query that will be processed “off-line” when system resources are available. The results will be stored in a Newline delimited JSON (NDJSON) bundle, and the initiator of the query will receive a URL that can be used to download the results. You can try this using a sample web app posted by the SMART group and shown in Figure 2.
From the outset, the purpose of the articles in this series was to introduce researchers from other fields to the exciting field of health informatics in the age of FHIR. This last article should help readers understand how the FHIR specification is expanding beyond direct patient care in ways that should be of interest to any researcher contemplating the use of clinical data.