

Mark Sagar is changing the way we look at computers by giving them faces—disconcertingly realistic human faces. Sagar first gained widespread recognition for his pioneering work in rendering faces for Hollywood movies, including Avatar and King Kong. With a Ph.D. degree in bioengineering and two Academy Awards under his belt, Sagar now directs a research lab at the University of Auckland, New Zealand, a combinatorial hub where artificial intelligence (AI), neuroscience, computer science, philosophy, and cognitive psychology intersect in creating interactive, intelligent technologies.
To follow the trajectory of Sagar’s technological innovations over the years is to see them go progressively deeper—the 21st century version of a Renaissance écorché and then some—with code acting as the sketch pencil. His digital smiles, for instance, are not simply virtuoso renderings that remind you of a good friend’s grin; they probe beneath surface appearance—all the way to the brain—informed by physiology, biomechanics, and neuroscience. Sagar designs with a knowledge of micromovements of facial muscles under the skin and of the pleasurelinked endorphins that accompany a smile. Ultimately, Sagar is pulling back the skin on human expression with a very specific purpose: to design human–computer interactions modeled after neural networks. You could call it AI with its own underlying artificial nervous system.
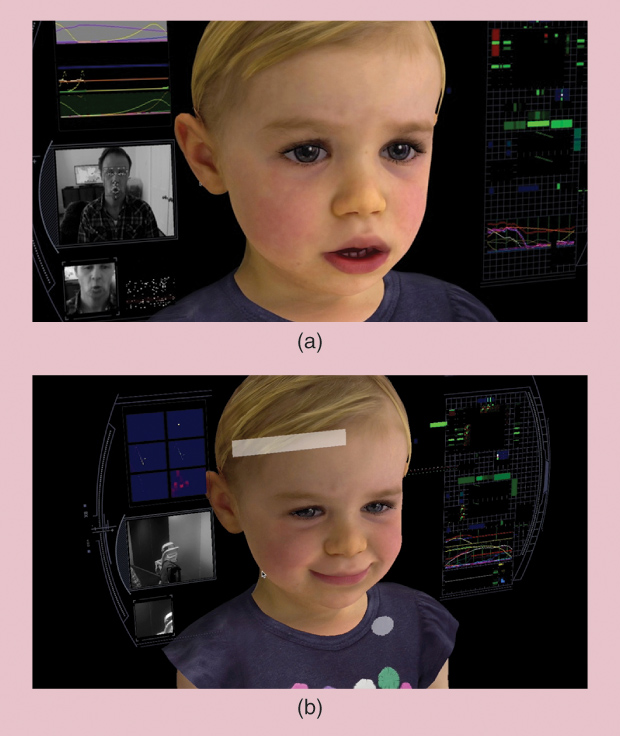
The most high-profile of those faces at the moment is BabyX, a digital embodiment of the truism that children are our future. It is the next generation of a real-time interactive system. A simulation of a downyhaired, rosy-cheeked infant, BabyX’s face and upper torso present on a computer monitor. It surpasses the AI chatbots of yore in its ability to respond to “digital-sensory” inputs. So, for example, BabyX can “see” a human user/interlocutor through its computer camera and respond to what it sees. BabyX can read a word you hold up in front of it. It can smile back at you. It will even get upset if you leave the room, just like a real baby. Most remarkably, the question driving the design of BabyX is not the usual “what’s the next cool thing we can get computers to do?” but a more audacious one: can we “teach” computers to learn in the ways that people do? BabyX’s algorithms are based upon human biological processes and the neural systems involved in learning and behavior. It is programmed to learn through interaction with its users, based on modes such as association, conditioning, and reinforcement.
I spoke to Mark Sagar to find out more about the thinking and work that have gone into the design of BabyX and the Auckland Face Simulator project at his Laboratory for Animate Technologies.
IEEE Pulse: Let’s talk about BabyX. Why a baby and not, say, an adult?
Mark Sagar (MS): There are multiple answers to that question, but, essentially, it’s to try to make a human simulation as simple as possible. One of the things we want to do is understand building blocks of human behavior, and so you really want to start at the beginning of social learning and social contact.
With a baby, you’re not dealing with the complex psychological masking that adults do. If it was an adult model, you’ve got to give it a lifetime of experience, all kinds of things that wouldn’t be possible yet.

We want to make something you can interact with at a certain level of complexity, and so a baby seemed like an appropriate age for that (see Figure 1). The main thing is to explore how different biologically motivated systems come together. We’re looking at how our behavior would emerge as the result of many different systems interacting at different scales. So, for example, a physiological state out of homeostatic imbalance is a primary driver—such as low blood sugar level driving the sensation of hunger, which drives searching for food. This overt behavior is linked to an internal state.
On top of that physiological state, you have experiential networks. You have learned different patterns in the environment, and some of those are rewarding, and some aren’t rewarding. And then there may be higher-level patterns, such as longer-term internal psychological goals.
Also, critically, there is interaction with a caregiver. If you think about mother–child interaction, so much is communicated through the voice and through the face. So how do we build a system that can learn and also includes that physiological basis? We want to look at this from a top-down and bottom-up approach: the behavior of a system results from activity in and between all these multiple layers of activity.
We’re building “toy models” of each part, trying to represent in the simplest possible way something that is still arguably a biological model—how these things fit together and how one thing might modulate another.
IEEE Pulse: When you talk about modeling an experiential network that has rewards in it, do you mean, for example, programming BabyX so that it can recognize when you say something like “Good job, baby”?
MS: Affect is one of the in-built teaching signals that we have. With parents, tone of voice is a really big teaching signal. And it works with different animals too; dogs will respond to tone of voice as well. So if you’re excited about something, you might go “woo!”’ and raise your voice. Modulating your voice is actually giving a teaching signal long before words are understood.
With BabyX, we incorporate those sort of affect-related signals: your expression, your intonation. Those signals are all highlighting that something’s important or something’s capturing attention. We use those signals to do things like, for example, change the dopamine level of our model, which modulates the neural networks, basically changing the learning rate of the neural networks (see Figure 2). So this is a theoretical model of how social interaction is actually modulating learning interactions.
IEEE Pulse: Can BabyX recognize things such as which pitches are pleasant or unpleasant?
MS: Yes, we assume that recognition of certain affect signals is innate. We know things like animals that see another animal baring their teeth will take that as a threat signal. The expression of these primary signals is also innate. We know things like blind people who have never seen another face will smile. We assume that those types of things have actually evolved, and, in a way, these constrain the design of BabyX.
One of the goals of BabyX is to try to show how a constrained architecture will actually lead to a learning system. The idea here is you could have completely random elements in how you learn, but then you look to nature and you go, well, what are the constraints on how people learn and how babies learn? And we’ve essentially got a template from nature that we look to as an example.
When we experience the world, there’s almost infinite information coming in. But if we pay attention to something, we’re reducing that information.
One of the things we really look at is the concept of embodied cognition. Much cognitive function can be explained through sensorimotor models that embody constraints, for example. Typically, a baby will do a whole bunch of seemingly random movements, but what she’s really doing is exploring her motor space and seeing the effect of that. So the baby might see her hand move, and then she starts gradually associating that her muscle movements are related to where she expects to see her hand. The baby starts building a model of her own world in that way. And then she will notice that her hand can move something because she’s getting feedback from the world, and she starts linking motor actions with the movement of an object. These types of things build up over time to add to her knowledge and abilities.
IEEE Pulse: One way to think about your work is that you’re creating a simulation, and the goal in incorporating this scaffolding of learning and knowledge from neuroscience is to create something as realistic as possible. But have you ever felt that in the process of designing BabyX, you might also go beyond the simulation and create something new in terms of how we could learn better?
MS: At the moment, we haven’t gone down that path. We’ve tried to be as general as possible. Essentially, what we can hope for out of this is to make an intuitively teachable computer. What is the signal that’s being fed back to create an event? And also, what is the sensory input into the system?
So if we humans get input from our eyes and ears and so forth, something in the computer world can have input from any source— it could be a temperature gauge, or it could be some feed from the Internet. The idea there is that we can combine arbitrary inputs to build mechanisms with multimodal association, in the way that humans associate sight and sound, for example. On a computer model, that could be some feed from the Internet associated with some feed from a sensor, but it’s essentially using the same learning architecture we’ve created for BabyX.
So that’s where we can start really abstracting BabyX to create a kind of nervous system, a digital nervous system, which can interact as a new type of creature in a way. One of the potential applications for this could be like a nervous system for the Internet of Things.
You could call the approach biomimetic. Instead of taking a more computer-science approach (in which you can apply any type of ideas you want and build up a system), we are trying to give things more of a biological basis—a system biologically inspired, in a way, because, of course, there’s lots of simplifications that you have to make.
IEEE Pulse: I’d love to talk a little more about applications for BabyX—or for the other technology you’re developing in your lab, the Auckland Face Simulator. I read that potential applications include everything from next-gen gaming characters to autism treatments. What applications will roll out first—or which ones would you love to see?
MS: We’re doing two different types of technology approaches in the lab, and one is BabyX, which is an exploration of how we tick. Then, on the other side, we’re building adult faces. With the Face Simulator, we’re exploring what happens if we put a face on Siri or connect a face to information technology (see Figure 3).
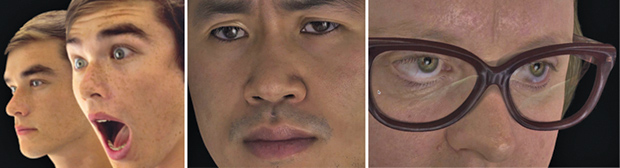
For example, if we have a face-to-face conversation, then my facial movements will actually give information about what might be important in what I’m saying. I might highlight that importance with an eyebrow raise or something similar, or it might be what I’m looking at when I’m referring to something. So those are examples where all the nonverbal aspects of communication are important. Imagine Siri with a face and all the extra information you’d get from that interaction.
So, applications of the technology could be an educational system for children, where they may not be able to read yet, but you can still convey information. Or it could be for elderly people that don’t want to use computers but if we make something a bit more human-like, then they can relate to it in a more intuitive, natural, easy-to-understand way.
IEEE Pulse: You’ve concentrated for quite some time on the face and face simulation, and I know you began with the eye when you were working on virtual surgery early in your studies. I’m curious about whether you have a favorite aspect of the face as you’ve become so immersed in it.
MS: Probably the thing I’ve studied the most would be the smile. And it’s probably the nicest thing you can study too! When you’re doing biomechanical simulation, the smile is really complex because the face has got so many layers of tissue with different material properties, and, when you smile, your whole face actually slides and bunches up, and it’s a very, very large deformation that happens. When you’re trying to simulate that, it’s quite challenging. The other thing with the smile is that smiles are very subtle, so the dynamics of the smile matter just as much as the form of the smile. But we did make models that can simulate realistic smiles.
IEEE Pulse: Do you feel like you’ve conquered this particular facial “challenge,” or is it still evolving?
MS: (laughs) I would never say I’ve conquered anything; it’s all about degrees. You want to get to a point where it can effectively communicate the emotion. In other words: if it really creates a good feeling when you see it.
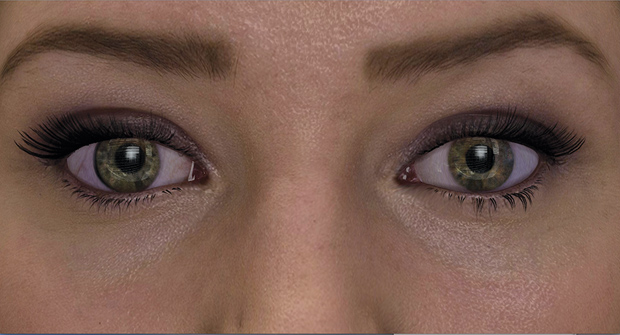
The other area that has been of real interest is the eye (Figure 4). So what we’ve tried to do in our latest model is to make eyes that you can really move right in on. We have the neural networks controlling pupil dilation and constriction and where the eyes are looking, and the neat thing is that they are linked to what the camera sees. So these eyes—not only can you zoom right into them, but they are also seeing you in a way.
It takes a lot of attention to detail and work to create these models. I’m very lucky to have a fantastic and talented team including engineers and artists, such as Oleg Efimov, who is very passionate about getting the details of the eyes just right. The eyes are what we’re really looking at to see if something’s conscious. Just by seeing somebody’s eyes alone, you can read an awful lot about how they’re feeling and what matters to them. It’s the most important area to get right.
IEEE Pulse: This must have affected how you interact with people in your everyday life. Do you think more about your own expressions, and do you observe things in people because you’ve studied faces so closely?
MS: Probably to a degree. It’s not a constant thing, but I do definitely notice certain things. I’ve always found faces fascinating.
IEEE Pulse: I was just thinking about empathy as you were talking. It’s almost as if a gauge of the success of your AI models and design is if you can witness a certain empathic response in the human user. Has that ever felt odd for your users or for you as you interact with your prototypes—to be feeling emotions that we’d normally feel for other people, but in response to a computer?
MS: That’s one of the interesting things, when people experience BabyX in person. When I do a live demonstration, I normally get a very big empathetic reaction from the audience. If I abandon the baby and she starts crying, people really get upset. It’s interesting because they know that they’re looking at an artificial model. They know it because I’ve just explained to them how we’ve been building it. But then they react like that, and they get a sense of relief when I come and comfort the computer baby.
Mike Seymour, who researches CGI human faces, has studied the audience reaction to BabyX. He has coined it “flooding the uncanny valley with emotion”—BabyX seems to bypass the “uncanny valley.” People have tapped into a different mode. It’s like you create this emotional connection that is almost sacred in some way and is independent of intellectualism or technology.
IEEE Pulse: What is it about BabyX that enables this “flooding the uncanny valley with emotion”—is it the whole package, or could you pinpoint a feature or two that you think gets people to that pitch of empathy?
MS: It’s really the whole thing. What we’re showing with BabyX is how all these different elements come together to make something that appears alive.
As AI develops and it comes more and more into our lives, these elements are going to become increasingly important to put into computer systems because you want to have computer systems tied back to human social values. If you think about how people interact in society, when somebody doesn’t have those social values, we tend to ostracize them.
Now at the moment, you’ve got AI programs that are just munching on lots of big data, and there’s no control over that. It’s literally just connecting data together without it being grounded in a social consequence. It may well be that future AI needs to have this human connection as part of that loop.
The amazing thing about computers is that they’re able to turn theories or instructions into process. When you see a process, the process is independent of the substrate. If I see a simulation of water flowing on a computer, I would still call what the water is doing “flow,” even though I know it’s a bunch of bits basically turning on and off. And so our work in the lab provokes questions such as, would you use a human behavioral description to describe what a machine is doing?
IEEE Pulse: Interesting concepts to consider. Last question: have you had any moments that felt absurd or crazy as you work with your prototypes?
MS: We constantly have bizarre moments in the lab because we’re making these faces, and when things go wrong, it’s not just a bug where the numbers are wrong, it’s actually something that looks like something. The face might have exploded in some way. There’s some extremely comical things that happen. I encourage people in the lab, every time something really stupid happens, to screenshot it, and, at some point, we’ll do a blooper video.
IEEE Pulse: The outtakes …
MS: Yeah. One of the really fascinating events was when I was showing my real daughter (who BabyX is based on) BabyX reading — recognizing—some words. Now my daughter couldn’t read those words, and when she saw her digital self read them, she just went completely quiet. She was deeply challenged by it.
IEEE Pulse: Wow.
MS: I still haven’t figured this out, but I think there is something there that has a powerful educational value. You could think about a virtual assistant to learning, or all kinds of things. It may be that, for certain children, that collaborative learner or assistant might really enable learning. This was just one of those unexpected things. I’d never even thought about how it might play out.
IEEE Pulse: I can imagine BabyX spawning another chapter in continental theory based on this new kind of “mirror stage.” You’re creating a whole new line of work for psychoanalysts and philosophers.
MS: (laughs)
IEEE Pulse: So interesting to talk to you. Thank you so much.